Exploring Goal Oriented Action Planning
Yes, F.E.A.R will be mentioned
I while ago I decided to take a break from graphics programming to engage in a small, one-off prototype. My choice landed on implementing Goal Oriented Action Planning, or GOAP for short, a game AI algorithm made famous by F.E.A.R over 20 years ago. I think most of us who played F.E.A.R back in the day (or possibly even in recent memory) recalls what felt like a very rich and interactive experience in regards to enemy behavior.
Alma still scares me
Luckily for us, Monolith Productions (RIP) was happy to talk about the secret sauce behind their success. The talk “Three States and a Plan: The AI of F.E.A.R.” from GDC 2006 walks us through how they did it.
The typical game AI techniques of the past could not meet the demands of the complexity desired for FEAR. Finite State Machines and A* are core AI systems in many games, and F.E.A.R. is no different. What sets F.E.A.R. apart is the fact that the Finite State Machine has only three states, and A* is used to plan actions as well as paths. Planning behavior in real-time allows characters in F.E.A.R. to adapt to the situation at hand. If the Player slams a door on a pursing enemy, the soldier can dynamically re-plan and decide to fire through the window, or flank through an alternate entrance. Empowering characters with real-time planning and problem solving abilities frees developers to focus on higher level squad behaviors, such as suppression fire, advancing cover, and search behaviors.
This gives us our motivation for exploring GOAP. While traditional Finite State Machines or Behavior Trees do allow for complex behavior they have an inherent cost in designing, authoring and maintaining each path the AI might take. With GOAP we instead break each task down into smaller actions that combined will reach our desired outcome. Running the planning and organization of these actions in real-time will allow us to string together a sequence that brings our agents to the desired outcome without having to explicitly author the path from each starting state to the desired end state. A classic example would be an agent that is hungry. They want to eat but first they must cook the food, which requires lighting a fire, which requires firewood, which requires chopping down a tree etc etc. The possibilities are virtually endless, in theory at least.
Theory
So now we know why GOAP is worth exploring, here is how it works in theory. Each agent has a starting state, a desired state and a set of available actions. Each action mutates the current state and has a cost associated with it. We use a pathfinding algorithm (for F.E.A.R it was A*) that finds the cheapest path from the starting state to the desired state. This is our plan, the set of actions for the agent to reach its goal. As the agent progresses through the plan we re-evaluate the current and desired states continuously to see if the plan needs to be updated. Maybe the agent was trying to find ammo to reload their gun but got hurt in the meanwhile. The priority changes from reloading to finding cover and healing itself, then going back to reloading.
Implementation
The real beauty is in the simplicity of both the theory and implementation of GOAP. This has some drawbacks that I will discuss in the end. All code samples are excerpts from my prototype built using Godot and C#.
We start with our states, starting and desired. In my case each agent holds a WorldState which is how the agents currently perceive the game world around them and their internals. The WorldState is in this case a simple HashMap of any Object.
1
2
3
4
5
public class WorldState
{
private Dictionary<string, object> _state = new Dictionary<string, object>();
...
}
You use it by simply adding the desired properties to the state. In this case it is simple booleans but this could be positions, other agents etc.
1
2
3
4
5
6
_worldState = new WorldState();
_worldState.Set("hasFood", false);
_worldState.Set("isHungry", true);
_goalState = new WorldState();
_goalState.Set("isHungry", false);
Next up we need agents. Our agent contains the current state, a list of all actions that are available for said agent, the current plan and the action that is currently in progress.
1
2
3
4
5
6
7
public class GOAPAgent<T>
{
public WorldState WorldState { get; private set; }
public List<GOAPAction<T>> Actions { get; private set; }
public List<GOAPAction<T>> CurrentPlan { get; set; }
public GOAPAction<T> CurrentAction { get; set; }
}
GOAPAgent<T> is used as component within the actual agent that requires the AI behavior.
1
2
3
4
public partial class Enemy : CharacterBody3D, INavigatable3D
{
private GOAPAgent<Enemy> _agent = null;
}
As can be seen from the GOAPAgent<T> definition T is required by GOAPAction<T>.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public abstract class GOAPAction<T> : IShallowCopyable<GOAPAction<T>>
{
public string Name { get; protected set; }
public abstract float GetCost(WorldState state);
public abstract bool CheckPreconditions(WorldState state);
public abstract bool ProceduralCondition(
WorldState currentState,
WorldState goalState,
T actor
);
public abstract WorldState ApplyEffects(WorldState state);
public abstract void EnterAction(GOAPAgent<T> agent, T actor);
public abstract void ExitAction(GOAPAgent<T> agent, T actor, bool interrupted = false);
public abstract bool Run(GOAPAgent<T> agent, T actor);
}
The brunt of the work happens within the actions. Agents are treated as pawns in this implementation where as long as they contain the necessary components required by an action, the action takes care of the rest. Let’s walk through the functions in actions one by one.
GetCostreturns the cost of the of the action used for calculating a new plan. This can either be a static value or calculated depending on theWorldState.CheckPreconditionsreturns if the action is possible for the currentWorldState. IfCheckPreconditionsreturnsfalsethe action is not considered for planning with the currentWorldState.ProceduralConditionruns additional checks using runtime information such as pathfinding to see if an agent is able to navigate to the necessary location to perform an action. If this fails the action is not considered for the plan.EnterActionandExitActionare triggered when starting and ending actions as the plan is executed. The agent’s underlying actor is used to set navigation targets, trigger animations etc.Runis looped every frame until the action is either finished or canceled by a new plan. It is especially important for long running actions such as moving agents.ApplyEffectsis used both for planning and when executing the plan. It takes the suppliedWorldStateand mutates it to the outcomeWorldState, such as adding an item to an inventory.
Finally there is the GOAPPlanner that is used to plan the actions for each agent. I chose to follow Monolith’s lead and use A* for the planning. The only difference to implementing a normal pathfinding A* is how to implement your heuristic. I think there is a lot of potential to play around here depending on what game you are making but I chose to simply implement a heuristic that counts the number of desired WorldState updates that are achieved by an action. The more desired updates from an action, the higher the heuristic.
The result can be seen in the images below. Here the agent wants to fetch an item in the room to the left but has to pass through the locked green door. To do so it plans the following actions:
- Walk to the key in the right room.
- Pickup the key and store it in its inventory
- Walk to the locked door
- Unlock the door
- Open the door
- Walk to the item
- Pickup the item and store it in its inventory
This might seem very verbose typing it all out but when put together dynamically it flows really well. I can confidently plop down an agent with an arbitrary WorldState and expect it to navigate to a desired state. The granularity of the actions obviously depends on the game itself. Something like opening a door could either be broken down into multiple actions (open, kick the door down, explosive breach etc) or rolled into one large action with internal variation.
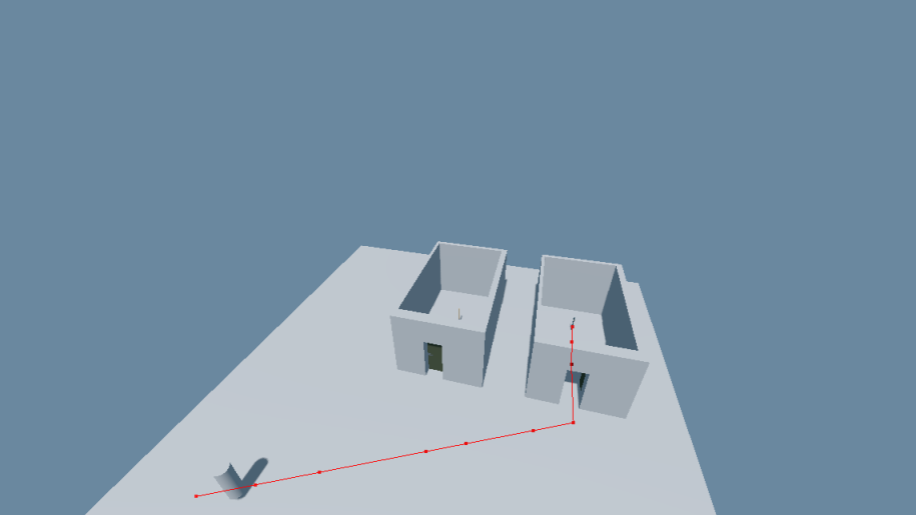 Keys are currently directly connected to doors instead of having to be discovered by the agent
Keys are currently directly connected to doors instead of having to be discovered by the agent
 The door was found when computing the initial path to the desired item
The door was found when computing the initial path to the desired item
 Home stretch!
Home stretch!
Locked doors
As usual, locked doors require a special shout out as problematic. Let’s assume we have a room with multiple ways to enter it, some of them locked and others requiring a costly detour. We need some way to calculate the compounding cost of unlocking doors that might recursively require unlocking other doors, extra navigation and other actions. For this prototype I chose to go with a simple approach of giving locked doors a heavy cost making the agent prefer alternative open paths if they were not too long. All navigation passing locked doors were then expanded recursively with the required actions to traverse them. This works fine for small worlds or few agents but does not scale very well if you have to traverse a large number of locked doors. Another approach could be to allow the planner to recursively look for paths that finds locked keys but with some maximum depth or time budget to avoid the search going on forever. Again though, this entirely depends on your game. My agents have perfect information of the state of the world in this prototype which means they could go on forever to find the absolute optimal path before springing into action.
 A randomly generated level from Life Pact showing a hard to handle case when locking many doors requiring backtracking
A randomly generated level from Life Pact showing a hard to handle case when locking many doors requiring backtracking
Sensors
I want to give a special shout out to combining GOAP with sensors. I believe that creating agents that have an imperfect view of the current WorldState, forcing them to either search for more information or act while lacking information, could potentially really add to the dynamic nature of the agents’ behavior. Simple things such as having to look for keys for locked doors instead of knowing where they are or being able to blind or deafen your enemies during combat encounters could wildly impact the plan of action for an agent in a dynamic manner.
Conclusion
So that’s the basics of GOAP. I feel this prototype gave me a good understanding of what the pros and cons of the algorithm might be. My main concerns, which seem to be echoed by the wider industry, are performance and predictability. Planning of individual agents can be parallelized and there is room for other, more optimized pathfinding algorithms than A* but you are ultimately limited in how many agents you can run, how many actions you can use and how complicated those actions can be. The second issue on predictability is both the strength and failing of the algorithm from a game design perspective. It is very hard to predict the exact outcome of adding actions to an agent’s table due to the dynamic nature of the algorithm. I can imagine that designers in many instances would prefer something that is easier controlled to achieve their desired outcomes such as FSMs or Behavior Trees. Both of these issues appear to, at least in part, be addressed by Hierarchical Task Networks (HTN) which I hope to be able to dive into in the future.
I hope you enjoyed this brief intro to Goal Oriented Action Planning. I recommend trying to implement it yourself to play around with it, it’s incredibly satisfying to just setup some simple tasks and watch the simulation play out before you. Let me know in the comments if you have worked with GOAP, HTN or any similar algorithms before, I would love to hear your experiences!